Ecoutez cet article avec la version audio illustrée disponible ici :
L’utilisation de modèles de distribution d’espèces, ou Species Distribution Models (SDM) dans la littérature scientifique, est particulièrement en vogue ces 20 dernières années et pour cause : ils permettent de donner une valeur d’habitabilité à une zone géographique pour une ou plusieurs espèces. Ainsi, il est théoriquement possible de connaître la distribution d’une espèce sur un territoire donné sans le prospecter dans son entièreté, ce qui est un gain de temps et de moyens énorme. Nous allons voir dans cet article la méthodologie et les idées derrière la création de ces modèles puis nous prendrons un exemple concret pour bien comprendre les conclusions que l’on peut en tirer.
Cet article est la seconde partie d’une série visant à expliquer et vulgariser ma thèse de doctorat que j’ai préparée aux Conservatoire et Jardin botaniques de la ville de Genève avec l’Université de la même ville, et que j’ai soutenue en Juillet 2022. L’entièreté de ma thèse (en anglais) est disponible gratuitement ici : https://archive-ouverte.unige.ch/unige:164478?fbclid=IwAR1tGQFsv27j66PlgjMkpQ_naeYOqTA-7WLX8uxpsUgjGUH8BB7bM-1iJBM.
La première partie traite de l’infrastructure écologique et est disponible en cliquant ici.
Pour ce deuxième volet, je vais me baser sur les parties introductives de ma thèse ainsi que sur un article (Sanguet et al., 2022) qui a été publié et qui est disponible ici : https://www.sciencedirect.com/science/article/pii/S2351989422002888. Vous pouvez le consulter pour avoir accès aux sources de ce travail et vous pouvez aussi me contacter pour plus d’informations.
Contact : phagophytos@gmail.com

« Globalement, tous les modèles sont faux, mais certains sont utiles »
« Essentially, all models are wrong, but some are useful. »
George EP Box
Un peu de contexte
La majeure partie de mon travail de thèse a consisté en la création de cartes de distribution des plantes d’un territoire appelé « Grand Genève » afin d’identifier les zones importantes pour la conservation de la biodiversité. J’ai donc passé la plupart de mon temps à utiliser et perfectionner des modèles de distribution d’espèces.
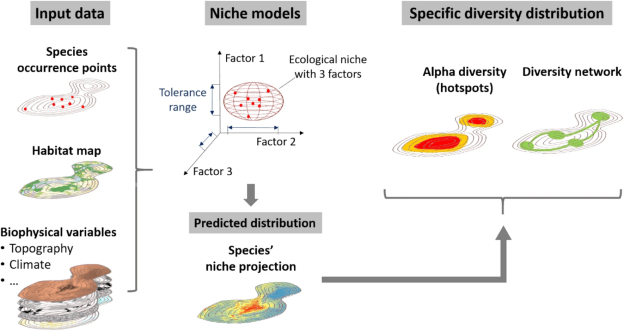
L’idée maîtresse de ces modèles est d’essayer de reconstruire la niche écologique réalisée des espèces. Quelques explications s’imposent.
La niche écologique est concept qui attribue un ensemble de valeurs environnementales à chacune des espèces, permettant d’expliquer pourquoi elles poussent dans un environnement bien spécifique. Par exemple, et pour caricaturer, les plantes tropicales apprécient des températures moyennes chaudes et stables, alors que les plantes tempérées préfèrent des températures plus basses et plus variables. Ainsi, chaque espèce possède théoriquement une niche écologique suffisamment différente des autres, permettant ainsi la coexistence de plusieurs espèces dans un même territoire. Si deux espèces ont une niche écologique et une distribution identiques, elles sont alors en compétition pour l’accès aux ressources. Les variables environnementales qui fabriquent la niche écologique sont infinies mais les plus importantes sont : la température, l’humidité, les caractéristiques du sol, la structure du territoire, la lumière, mais aussi les intéractions avec les autres organismes. Chaque espèce possède donc des valeurs environnementales optimales où elle sera la plus compétitive ce qui assure sa survie dans son habitat. Plus les valeurs environnementales s’éloignent de ses valeurs optimales, moins l’espèce est compétitive et plus elle a tendance à se faire remplacer par d’autres, plus compétitives.
On distingue deux types de niche écologique : la niche théorique et la niche réalisée. La première se base sur les tolérances d’une espèce en dehors de la nature, donc sans intéraction avec d’autres organismes, dans des conditions contrôlées. Par exemple, dans ces conditions, une espèce peut théoriquement supporter des températures disons de 5°C à 35°C sans mourir de chaud ni de froid. Cela représente en quelque sorte l’éventail des valeurs potentielles que peut supporter cette espèce. En revanche, elle est tellement peu compétitive aux extrêmes de sa niche écologique théorique qu’on ne la trouve dans la nature qu’entre des températures de 15°C à 25°C. Pourquoi ? Car elle est remplacée par d’autres espèces plus compétitives aux extrêmes. On appelle cela sa niche écologique réalisée ! Les modèles de distribution d’espèces calculent la niche écologique réalisée puisqu’ils se basent sur l’observation d’individus sauvages.
Maintenant que vous avez les bases, entrons dans le vif du sujet.

Comment ça fonctionne ?
Les données de base
Les modèles de distribution d’espèces se basent sur deux facteurs fondamentaux :
- Des variables environnementales, aussi appelées « prédicteurs », qui définissent du mieux possible la niche écologique réalisée de l’espèce ciblée. Il est globalement admis que ces variables doivent prendre en compte :
- Le climat et notamment les maximales, minimales et la variation des températures ainsi que la pluviométrie globale et les différences entre saisons sèches et humides. En effet, la fréquence des pluies est un paramètre absolument primordial qui permet de différencier les plantes poussant dans des zones tempérées de celles se trouvant dans les zones tropicales avec une alternance marquée de saisons sèche et humide.
- L’écologie de l’espèce et notamment ses habitats de prédilection, le type de sol ainsi que la structure de son écosystème (plutôt un habitat uniforme, des milieux dégradés, bien connectés etc.).
- La topographie, surtout dans les régions montagneuses ou vallonnées, avec par exemple l’exposition, la pente, la radiation solaire ou encore sa localisation relative en fonction du reste du territoire (sommet d’une colline ou fond de vallée).
2. Des observations d’individus de l’espèce dans la nature. On parle ici d’individus sauvages et non cultivés/en captivité. En effet, le modèle doit déterminer la niche écologique réalisée de l’espèce dans son environnement naturel et il faut pour cela des observations d’individus sauvages. Ces observations doivent respecter plusieurs points pour être de la meilleure qualité possible. Tout d’abord, elles doivent être précises et si possibles assez récentes pour ne pas biaiser les modèles avec des populations disparues qui vivaient dans des environnements différents. Ensuite, elles doivent être nombreuses, au minimum une trentaine, et bien réparties sur l’aire d’étude. Ce point est très important car si les observations sont toutes localisées au même endroit, et que cela ne représente pas la distribution réelle ou connue de l’espèce, le modèle va considérer les caractéristiques de cet endroit comme les seules viables. Au contraire, des observations diffuses sur le territoire, dans plusieurs localités, qui représentent à peu près toutes les zones connues/prospectées où se trouve l’espèce, permettent au modèle de mieux extraire les conditions environnementales importantes. Il existe la possibilité de fournir au modèle une « bias file » ou un fichier de biais, qui permet de montrer la concentration des observations et ainsi donner moins d’importance aux zones suréchantillonnées.
Le processus de modélisation
Avec ces deux informations, le modèle extraie les valeurs des variables environnementales aux localisations où se trouvent les observations des individus sauvages de l’espèce, on sait alors que ces valeurs font partie de sa niche écologique réalisée. Ces valeurs sont ensuite comparées à celles de points d’absence, c’est-à-dire des endroits où l’on sait que l’espèce ne se trouve pas, afin de dégager avec précision l’environnement optimal de l’espèce. Ces points d’absence sont parfois indisponibles car il est compliqué de s’assurer qu’une espèce n’est pas présente quelque part, d’autant plus pour des animaux mobiles par nature. Dans ce cas on utilise généralement des points dits « d’arrière plan » (background data), généralement 10’000 ou plus, qui définissent alors toutes les valeurs possibles de chaque variable environnementale en tout point de l’aire d’étude. On a donc des valeurs moyennes sur toute l’aire d’étude et des valeurs moyennes où se trouve l’espèce, si ces dernières sont statistiquement différentes des premières, cela montre que l’espèce a une préférence pour une variable donnée : on a alors une idée de sa niche écologique réalisée. Cette première étape, appelée « fit« , est fondamentale puisqu’elle est à la base de toutes les applications suivantes.
Une fois les valeurs environnementales de la niche écologique réalisée connues, le modèle les projette sur le territoire. Ainsi, toutes les zones qui collent aux conditions optimales de l’espèce sont considérées comme « très habitables » alors que les zones dont les conditions sont éloignées de l’optimum sont « peu habitables ». Et voilà, nous avons notre carte de distribution ! …. …. Non ?
Le résultat
Il est important de signaler ici que ce n’est pas la distribution réelle qui est modélisée, puisqu’elle est inconnue, mais bien l’habitabilité d’un territoire pour une espèce donnée en fonction des variables environnementales considérées. Le résultat pourrait s’interpréter comme une probabilité de présence d’une espèce en chaque point de la carte. En revanche, ce n’est pas parce qu’un endroit est très favorable au développement d’une espèce que l’on va nécessairement la trouver ! La carte résultante permet simplement d’estimer l’habitabilité d’une aire d’étude et cela peut être pratique pour la comparer dans différentes conditions (aujourd’hui VS dans le future avec le changement climatique) ou bien pour avoir une idée de nouvelles zones à prospecter pour trouver de nouvelles populations.
Attention tout de même, ces modèles peuvent tout à fait tourner en utilisant la localisation des boulangeries et le prix du carburant comme variable environnementale, même si cela n’a aucun sens écologique. Ce sont avant tout des outils, et il faut absolument s’assurer de la qualité et de la pertinence des données qu’on lui donne en amont pour pouvoir interpréter les résultats. Il existe de nombreuses méthodes pour tester la qualité des résultats, ce qui représente une étape primordiale et doit être fait à plusieurs reprises, mais nous ne nous attarderons pas sur cet aspect qui mériterait un article complet.
Les applications potentielles
Le résultat final s’apparente donc à une carte où chaque pixel possède une valeur qui définit le degré d’habitabilité du milieu. Si ces modèles sont effectués avec plusieurs espèces, il est alors possible de superposer ces cartes en les additionnant ce qui fait ressortir les zones les plus habitables pour un maximum d’espèces : on appelle ces zones des « hotspots » ou « points chauds » de biodiversité. Ces « hotspots » concentrent donc de nombreuses espèces et leur conservation est alors primordiale, bien qu’insuffisante si l’on souhaite aussi préserver des espèces rares que l’on ne trouve pas toujours dans ces milieux. Il est aussi possible d’utiliser ces modèles dans le futur et de comparer les distributions actuelles et futures pour définir la vulnérabilité des espèces aux changements globaux. C’est exactement ce que j’ai fait dans mon troisième chapitre de thèse donc nous en reparlerons. Il est aussi possible d’utiliser ces cartes pour en faire d’autres indices de biodiversité, des réseaux de conservation grâce à des logiciels de priorisation, ou bien de calculer la connectivité ou la fragmentation de la distribution de chaque espèce.
Les applications sont pour ainsi dire infinies et sont particulièrement intéressantes dans une optique de conservation de la biodiversité ou plus largement l’étude des écosystèmes et des espèces.
Mon travail
Introduction
Prenons un exemple pour bien comprendre ce que l’on peut faire avec ces modèles.
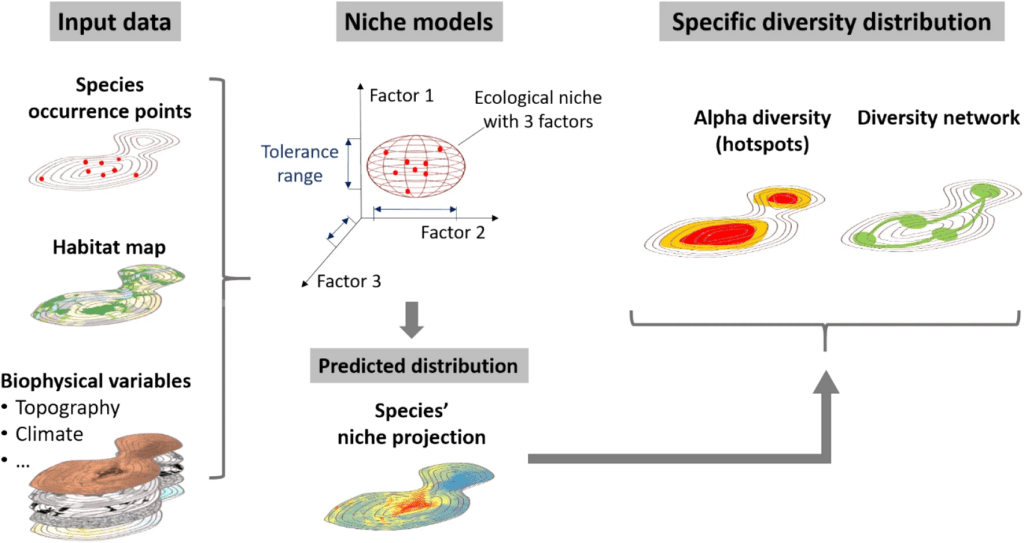
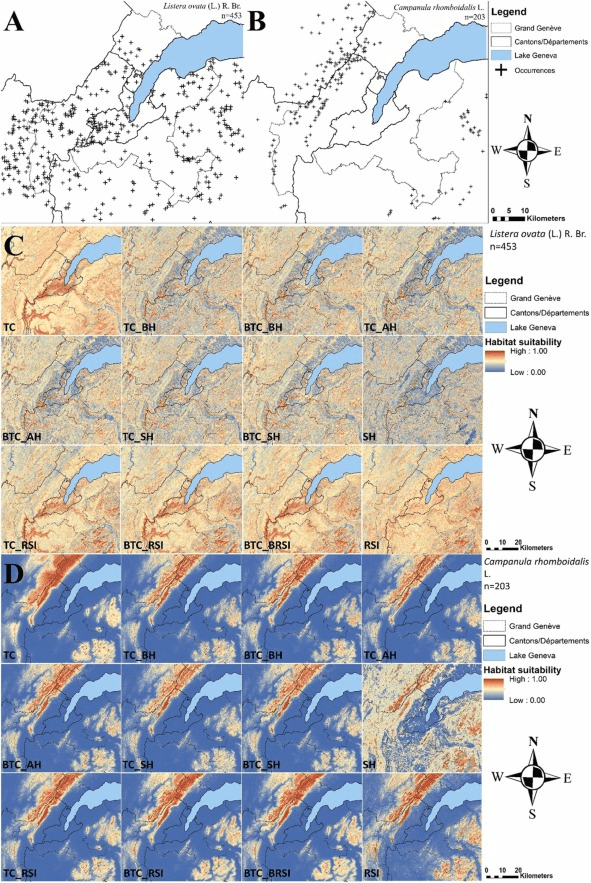
Durant ce travail j’ai modélisé la distribution de plusieurs espèces de plante sur le territoire du Grand Genève en utilisant différents prédicteurs (variables environnementales) afin de tester lesquels étaient les plus pertinents dans notre aire d’étude. C’est une étape cruciale si l’on veut ensuite pousser les analyses plus loin, par exemple en modélisant les distributions futures des espèces. Le Grand Genève est un territoire à cheval entre la France et la Suisse qui contient le canton de Genève, une partie du canton de Vaud, une partie de l’Ain et de la Haute-Savoie. Ce territoire inclue aussi une partie du Jura français. Il est donc simultanément sur deux pays, deux cantons, deux régions et trois départements ce qui complique beaucoup l’accès à des données homogènes.
Méthodes
La première étape a été de compiler les observations de 72 plantes dans la nature. Les espèces sélectionnées appartenaient à plusieurs grands groupes de plantes (Angiospermes = plantes à fleurs, Gymnospermes = conifères, et Ptéridophytes = fougères) et formes de vie : arbres, herbacées, annuelles, pérennes, lianes et arbustes. Les observations ont été triées pour ne garder que les plus précises (moins de 25 mètres de précision, ce qui correspond à la taille des pixels des prédicteurs) et les plus récentes (après l’an 2000).
Pourquoi 72 plantes ? 12 espèces ont été sélectionnées pour six groupes écologiques différents. L’idée était aussi de tester si le choix des prédicteurs variait en fonction des préférences écologiques de l’espèce. Les groupes écologiques comprenaient des espèces : rudérales (milieux perturbés), alpines (plantes d’altitude), hygrophytes (milieux humides), de prairies sèche et maigre c’est-à-dire pauvre en nutriments, de prairie grasse riche en nutriments, et enfin forestières (qui habitent dans les forêts).
Les prédicteurs ont été classifiés en 12 traitements à partir de trois grandes familles de variables environnementales : 1) des prédicteurs topopedo-climatiques, un mot bien compliqué mais qui correspond en fait au climat (températures, précipitations), à la topographie (pente, exposition) et à la pédologie (type de sol), 2) des prédicteurs biotiques correspondant aux habitats naturels et anthropiques de la région avec des classes plus ou moins précises et 3) des prédicteurs issus d’images satellites afin de tester si l’on peut utiliser cette nouvelle ressource en remplacement aux habitats naturels qui ne sont pas toujours cartographiés et disponibles. Ces 12 combinaisons ont permis de tester tous les mélanges possibles entre ces trois grands groupes de prédicteurs mais aussi l’importance de leur nombre (nombreux VS peu nombreux) et de leur précision (classe d’habitats très précise ou peu précise).
Les modélisations ont donc été faites 12 fois pour chacune des 72 espèces et une évaluation minutieuse de la qualité des résultats a été effectuée afin de voir : 1) quels sont les prédicteurs qui ont le mieux fonctionné, 2) comment ont réagi les différents groupes de plantes et 3) quelle était l’utilité des images satellites dans ce processus. Chacune des modélisations a été effectuée 10 fois de suite en changeant aléatoirement les observations utilisées pour créer le modèle et pour l’évaluer.
Les résultats
Quels prédicteurs utiliser ?
Les résultats montrent qu’une association de prédicteurs climatiques, topographiques, pédologiques et biotiques donne les meilleures distributions finales. Cela n’est pas tout à fait surprenant car il est globalement admis que cette association de prédicteurs est la plus intéressante. Si l’on regarde plus en détails, on se rend compte que les habitats ont joué un rôle particulièrement important dans la contribution des modèles, ce qui est aussi plutôt logique d’un point de vue naturaliste : on ne trouve pas des espèces forestières dans des prairies.
Le pic de qualité des modèles est atteint lorsque 8 habitats sont utilisés, en opposition à 4 ou 12. En effet, si les habitats sont trop peu précis, le modèle a du mal à cerner la présence de l’espèce mais si les habitats sont trop précis, le modèle à du mal à comprendre les préférences de la plante. Par exemple, une espèce qui pousse en forêt fermée risque de ne pas pousser en forêt ouverte (qui est un autre grand type de forêt). En revanche, cette espèce peut pousser dans différentes sous-catégories de forêt fermée (à conifères, à feuillus etc.). Il faut alors trouver le juste milieu en expérimentant. Il est difficile de faire des généralités car les résultats diffèrent en fonction des groupes écologiques (voir plus bas).
Quid des images satellites ?
Les images satellites sont de plus en plus utilisées dans les modélisations car elles peuvent permettre d’identifier des habitats naturels depuis l’espace et donc de s’affranchir de complications pour les cartographier manuellement avec un long travail de terrain et informatique. En revanche dans cette expérimentation, les images satellites ont été très mauvaises pour modéliser la distribution des espèces, surtout en comparaison à de « vrais » d’habitats dûment cartographié. Elles produisent en effet des modèles d’une qualité très inférieure et ne peuvent donc pas être utilisées en remplacement à des cartographies d’habitats, même si des améliorations pourraient être testées. Nous ne nous attarderons pas plus sur ce sujet mais n’hésitez pas à aller voir l’article si cela vous intéresse.
Toutes les plantes se modélisent-elles de la même manière ?
Les groupes écologiques ont montré des performances différentes, signifiant que le mode de vie des espèces a un impact sur la facilité avec laquelle on peut modéliser leur distribution.
Dans notre cas, les espèces alpines ou rudérales ont été plus faciles à modéliser que les espèces de milieux humides. En d’autres termes, les cartes de distribution des premières semblent plus pertinentes que celles des secondes. Cela peut être expliqué par le fait que les espèces alpines du jeu de données ne poussent qu’en pâturages d’altitude, où les milieux sont relativement uniformes ; ils ont donc peu d’impacts sur les modèles. De même, les plantes rudérales poussent dans des milieux urbains perturbés que l’on ne trouve qu’à basse altitude où l’influence humaine est grande. Pour ces deux groupes, les prédicteurs d’habitat contribuent peu à la performance globale du modèle, puisque c’est avant tout leur altitude qui explique leur distribution.
En revanche, les espèces de milieux humides sont plus difficiles à modéliser et beaucoup plus dépendantes de la distribution des habitats. En effet, ce qui explique ou non la présence d’une espèce de milieu humide est davantage l’humidité du milieu que l’altitude. Mais alors comment expliquer la qualité réduite de leurs modèles ? Et bien cela pourrait provenir de la difficulté que nous avons à cartographier les zones humides : 1) les pixels font 25 m² donc les zones humides plus petites ne sont pas utilisables par le modèle, 2) il peut exister des milieux humides « invisibles », car l’humidité se trouve en profondeur sous la terre, qui sont par essence difficiles à repérer et à cartographier, 3) les zones humides peuvent être temporaires et donc non classifiées comme telles dans les cartes des milieux.
Pour résumer, les résultats principaux de l’utilisation des modèles de distribution d’espèces (SDM) montrent que :
- Il faut tester plusieurs combinaisons de prédicteurs et prendre la combinaison qui a la meilleure performance moyenne, surtout lorsque l’on modélise beaucoup d’espèces d’un coup
- Connaître le territoire d’étude, notamment son relief et ses habitats, est primordial pour orienter la sélection des prédicteurs
- Connaître l’écologie des espèces que l’on étudie est tout aussi fondamental
- Les images satellites ne permettent pas de remplacer une vraie cartographie des habitats naturels, mais si cette dernière n’est pas disponible, elles peuvent tout de même être utilisées moyennant un travail en amont (voire article pour plus d’informations)
- Une association entre des prédicteurs topographiques, pédologiques, climatiques et biotiques donne les meilleurs résultats
Limites
Il est toujours bon dans la recherche scientifique de critiquer ses propres résultats et de montrer les limites associées aux grandes conclusions que l’on a tiré. Cela ne signifie pas que les résultats sont mauvais ou ne servent à rien, mais ils doivent être pris dans un contexte.
Tout d’abord, ce qui a été présenté ici ne reflètent que les résultats d’une étude, dans une zone géographique, à un moment donné. Même si les conclusions sont globalement en accord avec le reste de la littérature, l’expérience pourrait être améliorée en utilisant plus d’espèces, des espèces plus rares, d’autres prédicteurs, d’autres algorithmes de modélisation ou d’autres manières de mesurer la performance des modèles.
Plus généralement, les modèles ne remplaceront jamais une expertise de terrain. Ils permettent en revanche de poser un cadre commun à toutes les espèces et donc de les étudier simultanément en ayant la possibilité de les comparer.
Il faut bien comprendre que le résultat final est extrêmement versatile et dépend totalement de plusieurs éléments clés de la méthodologie :
- La qualité et la quantité des observations et les potentielles erreurs d’identification ou d’inattention dans l’envoi des données
- La qualité et la quantité des prédicteurs, puisque le modèle donnera forcément une carte finale peu importe les prédicteurs utilisés. Il faut donc bien connaître son territoire et ses espèces afin de déterminer si la distribution finale est plausible, en complément des mesures classiques de performance et de qualité
- La programmation, l’algorithme utilisé, le nombre de répétitions et les points d’absence doivent aussi être intelligemment utilisés
- Les autres potentiels biais sous-jacents comme : les biais spatiaux dus à des observations non représentatives de la distribution connue de l’espèce (voire le point qui traite de ce sujet dans le chapitre « comment ça marche » plus haut) ou bien la redondance des prédicteurs qui, même s’ils sont différents, représentent la même pression écologique (par exemple l’altitude et la température ne devraient pas être utilisées conjointement).
Pour toutes ces raisons, il est extrêmement important de connaître parfaitement sa zone d’étude, ses caractéristiques et les espèces étudiées. Il est fondamental de s’entourer de naturalistes locaux qui connaissent le territoire et sa dynamique passée. Il faut travailler en équipe et intelligemment pour ne pas risquer de tirer des conclusions à partir de résultats au mieux biaisés, au pire complètement faux.

